アナリティクスアソシエーション (a2i) > 活動報告 > オンライン >
活動報告
| 開催日時 | 2021/11/10(水) |
|---|
| 会場 | オンラインセミナー |
|---|
2021年11月10日に、オンラインセミナー「あなたにもできる機械学習 テキストマイニングとレコメンデーション」を開催いたしました。今回も多くの方々にご参加いただきました。皆様、ありがとうございました。
レポート執筆
二村 勇輔
株式会社Rejoui 代表取締役 菅 由紀子氏による2部構成のセミナーです。セミナーは、スライドでの説明とハンズオンのデモの2つで進みます。
前半は主に説明を中心に行い、後半はGoogle Colaboratoryの使い方について画面共有しながらセミナーが進みました。
菅 由紀子氏(株式会社Rejoui)
菅氏ははじめに、これからの社会に求められる人材像に触れます。
AIエンジニア、データアナリスト、DX人材など、様々な技術やデータを取り扱う人材が求められています。これらに共通して言えるのはAIとデータで、AIの根幹的な技術がこのセミナーの機械学習の世界だと述べたあと、セミナー本編に入ります。
まずは、機械学習とは何か、を説明します。
世の中にAI(人工知能)と呼ばれるものはたくさんあり、ただのルールベースの処理や自動化がAIと呼ばれることもありますが、機械学習の技術を使用していたり、統計解析の何らかのモデルに基づいて判断されているものが、本当の意味でのAIに近いものだと語ります。
AIと位置づけられるものの中に機械学習の技術があり、その中に教師あり学習、教師なし学習、強化学習など耳にしたことがある技法があります。基本的にはコンピュータにデータを渡し、それらに何らかの特徴などに基づいた法則性を見出すことによって、未知のデータがあったときに何らかの出力をしたり、データを似ている者同士に分けることが、機械学習です。
こうした混乱しやすい概念の説明には、身近なものを使用したわかりやすい図を用いて理解への難易度を下げるような資料になっています。
続いて、前述の教師あり学習・教師なし学習について、以下のように説明します。
・教師あり学習
たくさんの学習データを使って正解を教えることでコンピュータ自身が分類のモデルを作り出し、人間の判断を自動化することができる。法則性や共通項に対して、新たなデータが入ってきたときにどれくらいの当てはまりがあるのかを検討して、判断するもの。
・教師なし学習
コンピュータが何らかの分類を行うことを目的としている学習方法。「教師なし学習」では、データ間の関係性を見つけ出してさまざまな分類基準を作るため、その関係の意味や利用方法は人間次第。
次に機械学習の活用目的は以下の4点です。
1.分類
2.認識
3.予測
4.パターン発見
上記4つに対して、インプットとアウトプットをしっかりと理解していないと良い結果は出てきません。さらに補足として、今まではこれら4つのタスクがメインでしたが、最近では「生成・合成」が生まれてきました。実在しない人や模様を生成するというような、何かを生み出すことに使われることもあり、機械学習が面白くなってきたポイントでもありますがリスクでもある世界だと言います。
ここから、教師あり学習、教師なし学習それぞれについて、代表的な手法やロジックについて詳しい解説がありました。
教師あり学習では、「教師あり機械学習の基礎の基礎」と菅氏が言う回帰分析について丁寧に解説がありました。回帰分析の手計算ワークシートなども交えて、実際に計算してみることもできるようになっています。
教師なし学習では、最初の一歩としてユークリッド距離の求め方を取り上げました。
機械学習のプロセスは、以下の流れで行います。
1. データ収集
2. 単変量解析
3. 2変量解析
4. モデリング
5. 評価・解釈
1、2では、データ収集したものがきちんとしたデータセットになっているか確認します。異常値、外れ値の存在、欠損値がどの程度あるか、分布がどのようになっているのかを確認し、データ収集・クリーニングに戻って、新たなデータ収集を検討します。これを前処理と呼びます。
「前処理に笑うものは前処理に泣く」
「前処理なくして分析なし」
などと言われるように、非常に大事なことです。
3でデータとデータの相関関係を把握します。相関係数を求めるだけでなく、散布図を描くことで外れ値がないかを確認します。4のモデリングは数式を書くことで、識別をしたり分類を行う機械学習を実行することです。
これらを経て、結果の評価・解釈を行います。
5の結果の評価・解釈にあたり、教師あり機械学習の場合は、当たっている or 当たっていない、未知のデータに対してはそれを行うことができるかなどを評価、うまくいかなければ特徴を選び直したり、データを新たに集め直したり、学習するデータセットを変えたりなどすることで、より良いモデルになるようにまたデータを学習していきます。
教師なし機械学習の場合は、データがいくつに分割できているか? データがうまく分割されていなければパラメータ値を変えていくつかのデータに分け直すこともあります。こうした工程を経て良いものができれば、機械学習の結果としてクライアントやシステムに提示します。
以上が理論の説明として、前半が終了します。
第二部は、ハンズオンでGoogle Colaboratoryを使いながらセミナーが進みます。
参加者は事前に用意された資料を元に、実際に手を動かしながら学習していきます。
(Google ColaboratoryはPythonの環境構築を行うことなくPythonを実行できるサービスです)
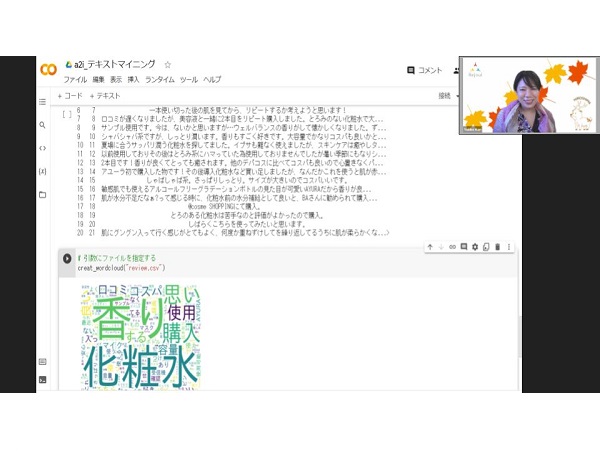
まず、Google Colaboratoryの基本操作の説明があり、テキストマイニングの実習が始まります。テキストマイニングとは大量の文書データから有益な情報を取り出す処理です。
テキストマイニングでは、レビューコメントのデータからWordCloudで描画するまでを実行しました。
・四則演算
・基本統計量の算出
・形態素解析
・極性辞書の取り込み
・アソシエーション分析
などの項目に沿って、菅氏からのレクチャーが進みます。エラーが出た時のフォローもあったため、初めての人でも学びやすい環境です。
極性辞書のレクチャー後に、BERTの紹介がありました。Googleが開発したもので、すでに大量に学習されているため、自然言語処理精度を非常に精度高くできます。数年前に発表された技術であり、業務の世界をがらりと変えた非常に面白いものです。
次に、アソシエーション分析に移ります。
アソシエーション分析は、膨大なデータの中からパターンや関係性を見つけるもので、マーケティングシーンでよく使用されます。菅氏はレコメンドエンジンの専門会社でビッグデータを扱っていたため、個人的に機械学習の手法でもっとも使用したものだと紹介します。
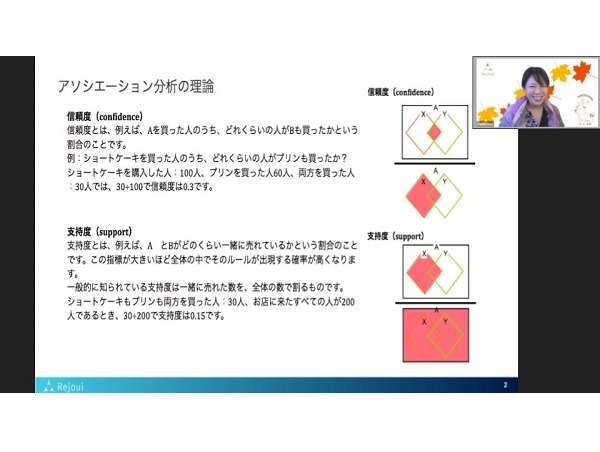
理論の尺度として、信頼度、支持度、リフトがあります。
・信頼度(confidence)
A を買った人のうち、どれくらいの人が B も買ったかという割合
・支持度(support)
A と B がどのくらい一緒に売れているかという割合
・リフト(lift)
A と B を一緒に買った人の割合は、全体の中で B を買った人の割合よりどれだけ多いかを倍率で示したもの
講義用資料には記載がなかった図が、配布用資料には記載されており、参加者への配慮が伝わります。
アソシエーション分析では、購入データを加工し、支持度やリフトを求め、関係グラフに可視化するところまでハンズオンで行いました。レクチャーに用いられた事例が商品購買情報だったため、業務への親近感を感じた方もいらっしゃったのではないでしょうか。
以上で菅氏のセミナーが終わり、質疑応答へと移ります。
Q. アルゴリズムを選択する際、決定木やSVMなど選択肢が複数あると思うのですが、その中から最も適切なアルゴリズムを選択するにはどうしたらよいのでしょうか?
定石があるのでしょうか?それとも経験を積むしかないのでしょうか?
A. 試行錯誤をして結果を見ながら判断していきます。残念ながら定石はありません。
また、GoogleからはAutoMLなど最適なアルゴリズムをデータ形式から自動判断するツールも出てきています。
Q. 先行商品、後続商品はどう決まりますか?
A. アプリオリのアルゴリズムの場合、時系列考慮はないです。
Q. 1ユーザーによって3アイテム以上購入された場合にはどうなりますか?
A. 1か0に変換することがほとんどです。3アイテムでの時系列のアソシエーションはよく見られますが、かなりの複雑な処理になります。順番考慮すると組み合わせが膨大になるのと発生確率が少なくなるので扱いが難しいです。
Q. 今回のアソシエーション分析はユーザー別でしたが、トランザクション別もできますか?
A. トランザクション別の処理も可能です。
トランザクション別にするとなお処理が重くなるのでご注意ください。
Q. 購買分析データは過去どのあたりまで遡って分析するものなのですか?
A. 課題によります。あればあるだけ見るのが良いという大前提です。
会員登録前後などの購買行動はお客様のストーリーによって異なりますが、起点となる日から全て見るのが基本姿勢だと思います。しかし、この2、3年のデータはコロナや災害でデータがめちゃくちゃになっているので注意してください。
例えば、時系列データで予測値を作るなら3年半以上必要です。顧客分析なら3ヶ月で一サイクルとし、そこから数えて2、3年くらい必要です。
回答の結論としては、最初からやるしかないと思います。
Q. プログラミングを深掘りしようとは思ってませんが、機械学習等を勉強するのにおすすめの書籍、おすすめの勉強法はありますか?
A. 「機械学習図鑑」がおすすめです。概念が理解できます。「エクセルでわかる機械学習」などもおすすめです。
■見て試してわかる機械学習アルゴリズムの仕組み 機械学習図鑑
Q.売上データを用意するときに日次や月次などのデータの用意はどうするのが良いですか?
A.予測させるデータより細かいデータがあったほうがよいです。
例えば、月別予測の場合、月別より細かい日次データがあったほうがよいです。
以上、数多くの質問にご回答いただき、機械学習を身近に感じるセミナーの幕が閉じました。

2026/07/15(水)
オンラインセミナー「はじめてのBigQuery生成AI分析 ― 費用と難しさへの不安を解消して、まず動かしてみよう」|2026/7/15(水)
「BigQueryでの分析が本命」とわかっていても、SQL、費用、設定の多さに身構えてしまう――そんな方に向けたセミナーです。 生成AIの進 …
2026/06/24(水)
オンラインセミナー「バイブコーディングで広告運用業務を再設計する ― 分析とデータ取得、2人の実践者に聞く」|2026/6/24(水)
「生成AIとバイブコーディングで広告運用の業務を変える」と話題にはなっていても、「何から始めればいいか」「本当に実務で使えるのか」「自分の環 …
2026/05/20(水)
セミナー「事故から学ぶ理想のGoogle タグ マネージャー運用 ― 計測トラブルを防ぐルール設計と運用の現実解」 【a2i DEEP Connection】|2026/5/20(水)
誰も全体を管理していない、複数の支援会社がそれぞれのルールで触っている、気付かないまま計測トラブルが起きている。そんなGoogle タグ マ …

【コラム】自社の経験と文脈を蓄積しよう ― BigQueryと生成AIで変わるマーケターとデータの関係
アナリティクスアソシエーション 大内 範行マーケティングの現場で、BigQueryに挑戦する非エンジニアの方が、少しずつ増えています。 BigQueryには優れた点がいくつもあります …
【a2i DEEP INSIGHT】「計る」から「繋ぐ/設計する」へ AI時代のマーケティング測定再定義(6月度ニュース深掘り)
発信元:メールマガジン2026年7月1日号より毎月a2iメンバーがピックアップした記事の中から、マーケターやアナリストが「DEEPな視点」で再考すべき5つのトピックを厳選してご紹介します …
【コラム】広告運用業務のインハウス化で、本当に自社に残すべきものは何か?
アナリティクスアソシエーション 大内 範行生成AIの登場によって、広告業務のインハウス化が注目されています。 P-MAXなど広告運用の自動化が進み、クリエイティブ制作にも生成AIが活 …

